A few days ago, I had a task to extract addresses from unstructured text, like the following:
Hey man! Joe lives here: 44 West 22nd Street, New York, NY 12345. Can you contact him now? If you need any help, call me on 12345678
The text in bold must be extracted from the sentence and returned as an address string. From the first view, it seems not so hard to do this using regular expressions, but when trying to do this, you can find out that the regular expression monster growing every moment, and the precision of the recognized address string is staying the same.
When you have semi-structured text where you can match some “labels” where the address begins, then the regular expression is a way to go. It’s fast, you don’t need a huge dataset of addresses to train the address chunker (more on that later), all you need is a predefined regular expression and then tune it to the cases where it fails.
So, as the regular expression is off the table, the other option is to use Natural Language Processing to process text and extract addresses. After spending some time getting familiar with NLP, it turns out it was the way I was thinking about this problem in the first place. Not as a rule you defined beforehand (regular expression) but as the classifier that can predict the class of a chunk of text based on the previous observation. Think of it as training on the same piece of text shown above, but with marks that this part of the text is addressed and others are just noise.
If you are not familiar with the NLP term and have never done anything with it in Python, I suggest getting a brief introduction in Natural Language Processing with Python book. This is a great resource to dive into the NLP field using the NLTK toolkit which is written in Python and contains a large number of examples.
Now, to train our classifier we need a dataset of tagged sentences in IOB format. This means that the sentence above must be tagged in a way to show the classifier where the address begins, continue, and ends.
Let’s see it in terms of a Python list:
{% highlight python %}
[(‘Hey’, ‘O’), (‘man’, ‘O’), (’!’, ‘O’), (‘Joe’, ‘O’), (’lives’, ‘O’),
(‘here’, ‘O’), (’:’, ‘O’), (‘44’, ‘B-GPE’),(‘West’, ‘I-GPE’),
(‘22nd’, ‘I-GPE’), (‘Street’, ‘I-GPE’), (’,’, ‘I-GPE’), (‘New’, ‘I-GPE’),
(‘York’, ‘I-GPE’), (’,’, ‘I-GPE’), (‘NY’, ‘I-GPE’), (‘12345’, ‘I-GPE’),
(’.’, ‘O’), (‘Can’, ‘O’), (‘you’, ‘O’), (‘contact’, ‘O’), (‘him’, ‘O’),
(’now’, ‘O’), (’?’, ‘O’), (‘If’, ‘O’), (‘you’, ‘O’), (’need’, ‘O’),
(‘any’, ‘O’), (‘help’, ‘O’), (’,’, ‘O’), (‘call’, ‘O’), (‘me’, ‘O’),
(‘on’, ‘O’), (‘12345678’, ‘O’)]
{% and highlight %}
The list contains several tuples where the first element is a word and the second is an IOB tag:
O - Outside of address;
B-GPE - Begin of address string;
**I-GPE **- Inside address string;
Using this dataset and feature extraction method, we show the classifier what chunk of text we want to extract and provide a way (feature detection method) to “map” features to IOB tags. This is a very simplified version of what is going on under the hood of the classifier, if you need more details, this post is used ClassifierBasedTagger which based on Naive Bayes classifier.
In the repository you can find an already compiled dataset of texts with US addresses. This is a pickled Python list that contains more than 9000 IOB-tagged sentences.
This list was compiled using different methods: Getting existing dataset of hotel/pizza contact info web pages; Generating fake text with fake addresses; Inserting random addresses to nltk.corpus.treebank corpus;
One idea that I haven’t tried is to scrape web site, which is using structured data and automatically retrieve addresses marked with address tag. So, this is already structured data, the only thing left is to convert it to IOB format and add it to the dataset.
The source code of chunker is pretty straightforward, all you need to do is get a brief introduction of NLP concepts and you are ready to go.
But what about results? There are cases when the part of the text which is not addressed is tagged as it is. The problem is in different formats of addresses and that’s only US addresses…One way to remove this ambiguity and to push the accuracy of address recognition to 100% is to use USPS database with a combination of regular expression and a dictionary of named geographic places including names, types, locations (gazetteer), etc.
RSPBot - source code.
In this post, we are going to build a Reddit bot for related posts suggestion. Think of it as a “related” page for posts in the subreddit. The idea is pretty simple: when someone creates a new post - the RSPBot will reply with a bunch of similar posts (if available).
Here is example for r/smallbusiness:
Original post:
Getting my small business bank account today. Should I go with a small credit union or a large bank?
Related posts:
Best small business bank account?
Bank recommendations for small business.
Best Small Business Bank
Which bank do you use for you small business and why?
Recommendations for Small Business Bank
Actually it’s a good way to measure how important this topic to the particular subreddit audience, what problem they are trying to solve and in what way.
But before moving to another topic I suggest taking a look at etiquette for Reddit bots. This is a set of rules and suggestions on what to do and what not with your bot. Don’t ignore those rules as banned bot is a dead sad bot :)
Let’s think about the following workflow: rspbot monitors the subreddit for new post submission, then it extracts post title and performs a search for similar posts in the same subreddit, then reply with a list of related posts. Sounds like an easy task, but think about the active subreddits where you receive a large number of new submissions and then try to search for the post titles, there is a chance that after some time you just flood Reddit with search API queries.
What if we just scrape subreddit titles beforehand and make it our database of post titles and create a mechanism to search through them and then reply with a bunch of similar topics? Sounds great as it simplifies our workflow, so we could perform all post titles matching on our local machine.
Scraping reddit posts is pretty simple as there is a great API documentation, but we will use Python API wrapper - PRAW, as it’s encapsulate all API query and provide easy to use programming interface. But what’s more important is that PRAW will split up your large request to multiple API calls each separated with some delay in order to not break Reddit API guidelines.
Here is an excerpt from subreddit scraper source code:
def add_comment_tree(root_comment, all_comments):
comment_prop = {'body': root_comment.body,
'ups': root_comment.ups}
if root_comment.replies:
comment_prop['comments'] = list()
for reply in root_comment.replies:
add_comment_tree(reply, comment_prop['comments'])
all_comments.append(comment_prop)
def get_submission_output(submission):
return {
'permalink': submission.permalink,
'title': submission.title,
'created': submission.created,
'url': submission.url,
'body': submission.selftext,
'ups': submission.ups,
'comments': list()
}
def save_submission(output, submission_id, output_path):
# flush to file with submission id as name
out_file = os.path.join(output_path, submission_id + ".json")
with open(out_file, "w") as fp:
json.dump(output, fp)
def parse_subreddit(subreddit, output_path, include_comments=True):
reddit = praw.Reddit(user_agent=auth['user_agent'], client_id=auth['client_id'],
client_secret=auth['secret_id'])
subreddit = reddit.subreddit(subreddit)
submissions = subreddit.submissions()
for submission in submissions:
print("Working on ... ", submission.title)
output = get_submission_output(submission)
if include_comments:
submission.comments.replace_more(limit=0)
for comment in submission.comments:
add_comment_tree(comment, output['comments'])
# flush to file with submission id as name
save_submission(output, submission.id, output_path)
if __name__ == '__main__':
parse_subreddit("smallbusiness", "/tmp/smallbusiness/", include_comments=False)<span data-mce-type="bookmark" id="mce_SELREST_start" data-mce-style="overflow:hidden;line-height:0" style="overflow:hidden;line-height:0" >&#65279;</span>
parse_subreddit method iterates over all posts in subreddit and extracts all information defined in get_submission_output method with optional comments list and saves it to JSON file with the file name as post ID.
If you don’t need comments, then just set include_comments to False as it speeds up scraper significantly.
Make sure you have created app on Reddit and received your client ID and client secret.
So, we have subreddit posts as a list of JSON files with all information we need, now we need to build a mechanism for searching through files and extracting similar posts as recommendations for users.
In rspbot we are converting text documents to a matrix of token occurrences and then use kernels as measures of similarity. So, basically we will use scikit-learn library class HashingVectorizer with linear_kernel method to get similarity matrix.
After we transformed the list of post titles into a matrix of numbers we can save this matrix as a binary file and then when running rspbot - just load this file and use it for getting similar posts. This will improve performance as we don’t need to parse the whole list of posts from JSON files to build matrix representation, we just load it from the file and re-use it from the previous run.
Make sure you have a basic understanding of how HashingVectorizer and linear_kernel work (check out scikit-learn tutorial on basic concepts) before moving to module source code.
Now we have a set of post titles as JSON files and a mechanism for matching similar posts, then next step would be to make a bot to listen for new submissions, get all related posts if available and then reply with a list of suggested topics.
With PRAW monitoring for new submissions is easy as writing for loop:
subreddit = reddit.subreddit('AskReddit')
for submission in subreddit.stream.submissions():
# do something with submission
Let’s summarize the whole bot “life” in a list of steps:
- Scrape the subreddit to list JSON files as related post suggestion database.
- Convert the list of JSON files to the matrix of token occurrence for finding related posts. This step is performed only for the first time the bot is started, latter we just re-use the existing matrix saved as a binary file.
- Monitor for new submissions; in case of new submission - convert to the matrix of token occurrence and combine it with the “old” matrix; search for related posts - if found - display a list of titles with URL.
In this post, I will discuss the clustering of points on the server side using a combination of PostgreSQL and PostGIS extensions. Then there will be presented NodeJS application, which simply pulls data from the database using a set of latitude and longitude describing the interested area.
Suppose you are working on a website that allows everyone to pay some fee to plant a tree in the chosen location. For each tree, there is a pin on a map with a tree marker and the name of a generous person who skipped morning coffee for the sake of restoring forests around the world. Now, imagine for a moment when your website became popular and you have 10.000 trees planted in some small area, now your map looks like this:
 Ughhh, where on earth are those trees located?
Ughhh, where on earth are those trees located?
Wouldn’t it be better to gather trees into some kind of bubble, and put a number of trees on it, so the person could distinguish the high density of trees and make a decision if that’s a good place to plant another one?
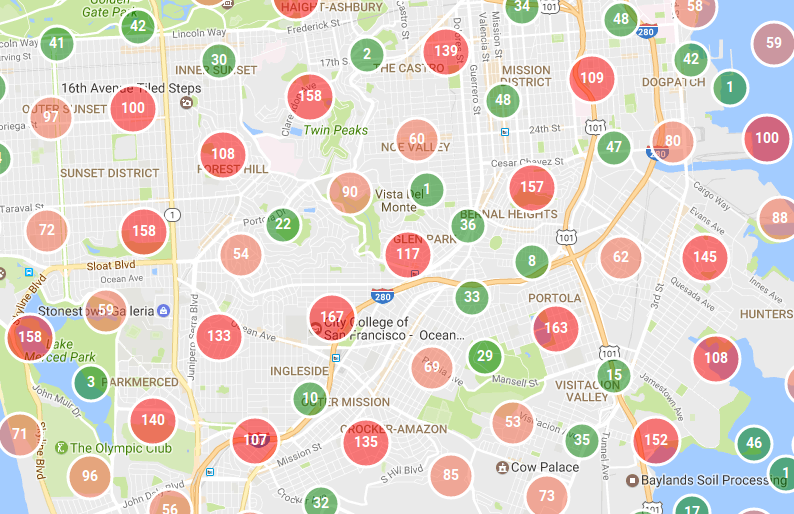 yes, that’s much better
yes, that’s much better
Here is the list of what needs to be installed beforehand:
- PostgreSQL
- PostGIS extension
- NodeJS
When the installation of PostgreSQL + PostGIS is done, we need to create a new database and enable the PostGIS extension. Now fire up psql in the terminal and type the following commands:
# start psql with default postgres user
psql -U postgres
# create a database where our places will be located
CREATE DATABASE trees;
# work on trees database
\connect trees;
# now enable PostGIS extension, so we can use all spatial functions, data types, etc
CREATE EXTENSION postgis;
In our case there will be used pretty simple clustering approach:
- Get any point that is not part of the existing cluster.
- Find all points in a predefined radius that is not part of the existing cluster.
- Mark found points that belong to a particular cluster.
- Repeat while there will be no free points without a cluster.
Before start writing SQL queries, we need to understand the basic idea of clustering points. There will be implemented dummy approach to finding points in a specific radius and this radius will be defined for each zoom level. So, when on zoom level two: the radius will be 100 km and then while zooming in the radius will be approximately divided by two. This is the slow solution as for each zoom level we need to gather all points using different radii, the more optimized solution will be clustering on the largest zoom level and then using clustered points as input to clustering for the upper zoom level, and so on.
Now we want to create a table named places, with place latitude and longitude and cluster id for each zoom level. Cluster id is an additional column to identify the cluster this point belongs to. For each zoom level, the additional table will be created with the name clusters_zoom
-- create table places and columns named cluster<n>
-- where n - is the cluster for a specific zoom level.
-- In our case, we want to cluster points in the zoom level range [2..16]
CREATE TABLE places(id SERIAL PRIMARY KEY,
place GEOGRAPHY,
cluster2 INTEGER,
cluster3 INTEGER,
cluster4 INTEGER,
cluster5 INTEGER,
cluster6 INTEGER,
cluster7 INTEGER,
cluster8 INTEGER,
cluster9 INTEGER,
cluster10 INTEGER,
cluster11 INTEGER,
cluster12 INTEGER,
cluster13 INTEGER,
cluster14 INTEGER,
cluster15 INTEGER,
cluster16 INTEGER,
dummy INTEGER);
-- create a table for each zoom level with the following fields:
-- cluster: id of this cluster, this will be stored in cluster<n> column
-- places table.
-- pt_count: number of points in this cluster
-- centroid: average position of all the points in the cluster
CREATE TABLE clusters_zoom_2(cluster SERIAL PRIMARY KEY,
pt_count INTEGER,
centroid GEOMETRY);
First of all, we need sample data with places we want to cluster. The easiest way is to generate random points in the predefined bounding box. In our example the bounding box will be located in San Francisco:
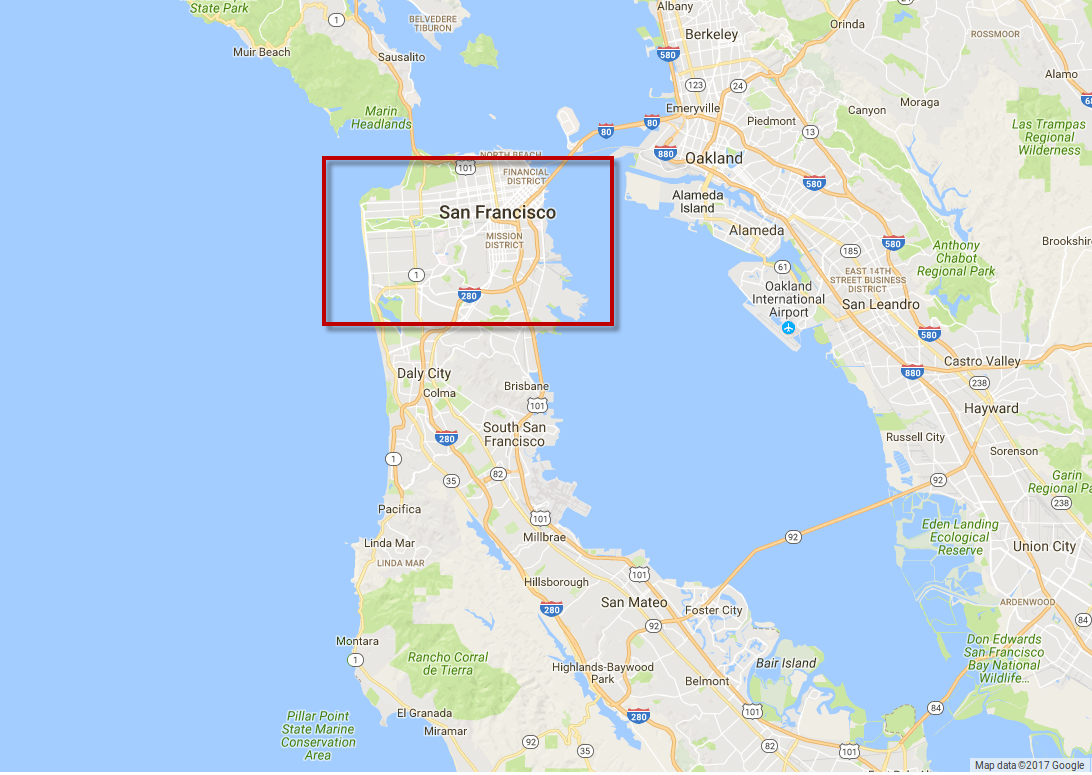 Sample data generated in the bounding box.
Sample data generated in the bounding box.
-- generate 10.000 random points in a bounding box with coordinates (longitude, latitude):
-- south-west: (-122.51478829956056, 37.686456995336954)
-- north-east: (-122.3220125732422, 37.79505521136725)
DO
$do$
BEGIN
FOR i IN 1..10000 LOOP
INSERT INTO places(place, dummy) VALUES (ST_MakePoint(
random()*(-122.3220125732422 - -122.51478829956056) + -122.51478829956056,
random()*(37.79505521136725 - 37.686456995336954) + 37.686456995336954
), i);
END LOOP;
END
$do$;
-- create an index on the places table
CREATE INDEX places_index ON places USING GIST (place);
Here is the main SQL function which is executed for each zoom level and gathers points into clusters with the predefined radius. In this example, the function is hard-coded for zoom level two and will be automated to execute for each zoom level in NodeJS module.
The make_cluster function is pretty straightforward:
All points are gathered using ST_DWithin function, which returns all geometries within the specified distance of one another. Pay attention to the fact that ST_DWithin takes as input geometry or geography type as the first parameter and distance as the last one. In our case, we use geography as we need to measure distance in meters.
After the new cluster is created then the clusters_zoom and places tables are updated with the new cluster id.
CREATE FUNCTION make_cluster2() RETURNS INTEGER AS
$$
DECLARE start_place GEOGRAPHY;
DECLARE cluster_id INTEGER;
DECLARE ids INTEGER[];
BEGIN
SELECT place INTO start_place FROM places WHERE cluster2 IS NULL limit 1;
IF start_place is NULL THEN
RETURN -1;
END IF;
SELECT array_agg(id) INTO ids FROM places WHERE cluster2 is NULL AND ST_DWithin(start_place, place, 100000);
INSERT INTO clusters_zoom_2(pt_count, centroid)
SELECT count(place), ST_Centroid(ST_Union(place::geometry)) FROM places, unnest(ids) as pid
WHERE id = pid
RETURNING cluster INTO cluster_id;
UPDATE places SET cluster2 = cluster_id FROM unnest(ids) as pid WHERE id = pid;
RETURN cluster_id;
END;
$$ LANGUAGE plpgsql;
Now, we are running this function to fill clusters_zoom table, while there exists points without cluster assigned to it:
DO
$do$
DECLARE cluster_id INTEGER;
BEGIN
SELECT 0 INTO cluster_id;
WHILE cluster_id != -1
LOOP
SELECT make_cluster2() INTO cluster_id;
END LOOP;
END
$do$;
Let’s assume that we have a table with all trees’ latitude, longitude, and some additional data specified by the user. What we want is to start the clustering process in the background as it takes some time to finish and then notify the user that all data was processed successfully.
In order to do this, we can create a separate module called clusterapp.js which will be running as a background process with a database connection string as an input parameter.
Before running clusterapp.js the following Node modules need to be installed:
The source code is pretty simple and automates SQL queries from the steps above:
var fs = require('fs');
var pgp = require('pg-promise')();
var db;
// predefined clustering radius for each zoom level (in meters)
var zoom_level_radius =
{
16: 100,
15: 200,
14: 500,
13: 1000,
12: 2000,
11: 3000,
10: 4000,
9: 7000,
8: 15000,
7: 25000,
6: 50000,
5: 100000,
4: 200000,
3: 400000,
2: 700000
};
process.on('config', (config, callback) => {
console.log('clusterapp: Configuration: ', config);
// connecting to PostgreSQL instance
// example: postgres://dbname:dbpassword@localhost:5432/places
db = pgp(config['connection_string']);
callback();
start_clustering();
});
String.prototype.format = function()
{
var formatted = this;
for (var i = 0; i < arguments.length; i++) {
var regexp = new RegExp('\\{'+i+'\\}', 'gi');
formatted = formatted.replace(regexp, arguments[i]);
}
return formatted;
};
// create a cluster table for each zoom level
function create_cluster_zooom_tables() {
db.task(t => {
return t.batch([
t.none("CREATE TABLE IF NOT EXISTS clusters_zoom_$1(cluster SERIAL PRIMARY KEY, pt_count INTEGER," +
" centroid GEOMETRY, classify INTEGER);", [2]),
t.none("CREATE TABLE IF NOT EXISTS clusters_zoom_$1(cluster SERIAL PRIMARY KEY, pt_count INTEGER," +
" centroid GEOMETRY, classify INTEGER);", [3]),
t.none("CREATE TABLE IF NOT EXISTS clusters_zoom_$1(cluster SERIAL PRIMARY KEY, pt_count INTEGER," +
" centroid GEOMETRY, classify INTEGER);", [4]),
t.none("CREATE TABLE IF NOT EXISTS clusters_zoom_$1(cluster SERIAL PRIMARY KEY, pt_count INTEGER," +
" centroid GEOMETRY, classify INTEGER);", [5]),
t.none("CREATE TABLE IF NOT EXISTS clusters_zoom_$1(cluster SERIAL PRIMARY KEY, pt_count INTEGER," +
" centroid GEOMETRY, classify INTEGER);", [6]),
t.none("CREATE TABLE IF NOT EXISTS clusters_zoom_$1(cluster SERIAL PRIMARY KEY, pt_count INTEGER," +
" centroid GEOMETRY, classify INTEGER);", [7]),
t.none("CREATE TABLE IF NOT EXISTS clusters_zoom_$1(cluster SERIAL PRIMARY KEY, pt_count INTEGER," +
" centroid GEOMETRY, classify INTEGER);", [8]),
t.none("CREATE TABLE IF NOT EXISTS clusters_zoom_$1(cluster SERIAL PRIMARY KEY, pt_count INTEGER," +
" centroid GEOMETRY, classify INTEGER);", [9]),
t.none("CREATE TABLE IF NOT EXISTS clusters_zoom_$1(cluster SERIAL PRIMARY KEY, pt_count INTEGER," +
" centroid GEOMETRY, classify INTEGER);", [10]),
t.none("CREATE TABLE IF NOT EXISTS clusters_zoom_$1(cluster SERIAL PRIMARY KEY, pt_count INTEGER," +
" centroid GEOMETRY, classify INTEGER);", [11]),
t.none("CREATE TABLE IF NOT EXISTS clusters_zoom_$1(cluster SERIAL PRIMARY KEY, pt_count INTEGER," +
" centroid GEOMETRY, classify INTEGER);", [12]),
t.none("CREATE TABLE IF NOT EXISTS clusters_zoom_$1(cluster SERIAL PRIMARY KEY, pt_count INTEGER," +
" centroid GEOMETRY, classify INTEGER);", [13]),
t.none("CREATE TABLE IF NOT EXISTS clusters_zoom_$1(cluster SERIAL PRIMARY KEY, pt_count INTEGER," +
" centroid GEOMETRY, classify INTEGER);", [14]),
t.none("CREATE TABLE IF NOT EXISTS clusters_zoom_$1(cluster SERIAL PRIMARY KEY, pt_count INTEGER," +
" centroid GEOMETRY, classify INTEGER);", [15]),
t.none("CREATE TABLE IF NOT EXISTS clusters_zoom_$1(cluster SERIAL PRIMARY KEY, pt_count INTEGER," +
" centroid GEOMETRY, classify INTEGER);", [16])
]);
}).then(data => {
console.log("create_cluster_zooom_tables: cluster tables created: " + data);
}).catch(error => {
console.log("create_cluster_zooom_tables:ERROR: " + error);
finish_clustering({'ERROR': 'Creating tables failed: ' + error});
});
}
// create make_cluster function for each zoom level
function create_cluster_functions()
{
var cluster_func_query =
"CREATE OR REPLACE FUNCTION make_cluster{0}() RETURNS INTEGER AS\n" +
"$$\n" +
"DECLARE start_place GEOGRAPHY;\n" +
"DECLARE cluster_id INTEGER;\n" +
"DECLARE ids INTEGER[];\n" +
"BEGIN\n" +
"SELECT place INTO start_place FROM places WHERE cluster{0} IS NULL limit 1;\n" +
"IF start_place is NULL THEN\n" +
"RETURN -1;\n" +
"END IF;\n" +
"SELECT array_agg(id) INTO ids FROM places WHERE cluster{0} is NULL AND ST_DWithin(start_place, place, {1});" +
"INSERT INTO clusters_zoom_{0}(pt_count, centroid)\n" +
"SELECT count(place), ST_Centroid(ST_Union(place::geometry)) FROM places, unnest(ids) as pid\n" +
"WHERE id = pid\n" +
"RETURNING cluster INTO cluster_id;\n" +
"UPDATE places SET cluster{0} = cluster_id FROM unnest(ids) as pid WHERE id = pid;\n" +
"RETURN cluster_id;\n" +
"END;\n" +
"$$ LANGUAGE plpgsql";
for (var zoom_level in zoom_level_radius)
{
var query_create_func = cluster_func_query.format(zoom_level, zoom_level_radius[zoom_level]);
db.none(query_create_func)
.then(result => {
console.log("create_cluster_functions: function created successfully");
})
.catch(error => {
console.log('create_cluster_functions: Creating clustring function failed due: ' + error);
finish_clustering({'ERROR': 'Creating functions failed: ' + error});
});
}
}
// creating cluster for each zoom level
function make_clusters()
{
var query =
"DO\n" +
"$do$\n" +
"DECLARE cluster_id INTEGER;\n" +
"BEGIN\n" +
"SELECT 0 INTO cluster_id;\n" +
"WHILE cluster_id != -1\n" +
"LOOP\n" +
"SELECT make_cluster$1() INTO cluster_id;\n" +
"END LOOP;\n" +
"END\n" +
"$do$;";
db.task(t => {
return t.batch([
t.none(query, [2]),
t.none(query, [3]),
t.none(query, [4]),
t.none(query, [5]),
t.none(query, [6]),
t.none(query, [7]),
t.none(query, [8]),
t.none(query, [9]),
t.none(query, [10]),
t.none(query, [11]),
t.none(query, [12]),
t.none(query, [13]),
t.none(query, [14]),
t.none(query, [15]),
t.none(query, [16])
]);
}).then(data => {
console.log("make_clusters: cluster created: " + data);
finish_clustering({'OK': ''});
}).catch(error => {
console.log("make_clusters:ERROR: " + error);
finish_clustering({'ERROR': 'Creating clusters failed: ' + error});
});
}
function start_clustering()
{
create_cluster_zooom_tables();
create_cluster_functions();
make_clusters();
}
function finish_clustering(status)
{
pgp.end();
process.send({'status': status});
}
After the clustering process is done we need to think about how to use it in our application. So, we have a backend as PostgreSQL database with a bunch of tables with clustered points and we need an API layer in order to retrieve clusters for the selected area and specific zoom level.
In order to gather all points in a specific area, we can use PostGIS && bounding box intersect operator on centroid from clustered points table and actual bounding box of the interested area created using ST_MakeEnvelope function.
Here is the full query:
-- get all clusters for the second zoom level in the area near San Francisco
SELECT cluster,
pt_count,
centroid
FROM clusters_zoom_2
WHERE centroid && ST_MakeEnvelope(-122.51478829956056, 37.686456995336954,
-122.3220125732422, 37.79505521136725, 4326);
In the NodeJS implementation we create api.js module with two endpoints:
- clusters: Getting all clusters at zoom level and bounding box passed as parameter.
- places: Getting original, non-clustered data at a specific zoom level and bounding box.
var express = require('express');
var router = express.Router();
var pgp = require('pg-promise')();
var backgrounder = require('backgrounder');
var GeoJSON = require('geojson');
// database connection parameters
var db = pgp('postgres://dbname:dbpassword@localhost:5432/places');
// optimization: define buffer radius for each zoom level
// when retrieving data for a specific bounding box
var zoom_level_buffer_radius =
{
16: 1000,
15: 1000,
14: 1000,
13: 1000,
12: 1000,
11: 1500,
10: 2000,
9: 3000,
8: 5000,
7: 12000,
6: 25000,
5: 50000,
4: 100000,
3: 100000,
2: 100000
};
// zoom: zoom level
// ne_lat, ne_lng: north east latitude and longitude
// sw_lat, sw_lng: south west latitude and longitude
// http://localhost:3000/api/clusters?id=&zoom=2&ne_lat=-21.32940556631426&ne_lng=146.66655859374998&sw_lat=-29.266381110600395&sw_lng=115.42144140624998
router.get('/clusters', function(req, res, next) {
let query_get_clusters = "SELECT cluster, pt_count, ST_X(centroid) as lng, ST_Y(centroid) as lat FROM \n" +
"clusters_zoom_$1 WHERE \n" +
"centroid && ST_MakeEnvelope($2, $3, $4, $5, 4326);";
let query_get_buffer = "SELECT ST_XMin(bu::geometry) as sw_lng,\n" +
"ST_YMin(bu::geometry) as sw_lat, ST_XMax(bu::geometry) as ne_lng,\n" +
"ST_YMax(bu::geometry) as ne_lat FROM\n" +
"ST_Buffer(ST_GeographyFromText(ST_AsEWKT(ST_MakeEnvelope($1, $2, $3, $4, 4326))), 1000) as bu;"
db.manyOrNone(query_get_buffer, [parseFloat(req.query['sw_lng']),
parseFloat(req.query['sw_lat']),
parseFloat(req.query['ne_lng']),
parseFloat(req.query['ne_lat']),
zoom_level_buffer_radius[parseInt(req.query['zoom'])]])
.then(buffered_box_data => {
db_connection.manyOrNone(query_get_clusters, [parseInt(req.query['zoom']),
buffered_box_data[0].sw_lng,
buffered_box_data[0].sw_lat,
buffered_box_data[0].ne_lng,
buffered_box_data[0].ne_lat])
.then(clusters_data => {
var result = GeoJSON.parse(clusters_data, {Point: ['lat', 'lng']});
result['buffered_bbox'] = [buffered_box_data[0].sw_lng,
buffered_box_data[0].sw_lat,
buffered_box_data[0].ne_lng,
buffered_box_data[0].ne_lat];
res.json(result);
}).catch(error => {
console.log(error);
res.json({'ERROR': 'Invalid request'});
});
}).catch(error => {
console.log(error);
res.json({'ERROR': 'Invalid request'});
});
});
// ne_lat, ne_lng: north east latitude and longitude
// sw_lat, sw_lng: south west latitude and longitude
// http://localhost:3000/api/places?id=&ne_lat=-21.32940556631426&ne_lng=146.66655859374998&sw_lat=-29.266381110600395&sw_lng=115.42144140624998
router.get('/places', function(req, res, next) {
let query_string = "SELECT id, ST_X(place::geometry) as lng, ST_Y(place::geometry) as lat \n" +
"FROM places WHERE place && ST_MakeEnvelope($1, $2, $3, $4, 4326);";
db.manyOrNone(query_string, [parseFloat(req.query['sw_lng']),
parseFloat(req.query['sw_lat']),
parseFloat(req.query['ne_lng']),
parseFloat(req.query['ne_lat'])])
.then(data => {
res.json(GeoJSON.parse(data, {Point: ['lat', 'lng']}));
}).catch(error => {
res.json({'ERROR': 'Invalid request'});
});
});
module.exports = router;
Now, you can run the api.js module and start testing queries in your browser. The response result for each query will be GeoJSON with data that was pulled from the database.
It doesn’t matter what map provider you are using as you have server-side clustering with API layer on top of it.
Here is basic example using google maps, which is listening on bounds_changed event and getting all clusters inside current bounding box:
</pre>
<pre><!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<style>
#map {
height: 800px;
width: 80%;
}
</style>
</head>
<body>
<div id="map"></div>
<script>
var gmap;
function show_clusters(zoom, ne_lat, ne_lng, sw_lat, sw_lng, bounds) {
http_request = new XMLHttpRequest();
http_request.onreadystatechange = function() {
if (this.readyState === XMLHttpRequest.DONE) {
if (this.status === 200) {
var response = JSON.parse(this.responseText);
if (response.hasOwnProperty('ERROR')) {
console.log('ERROR: ', response['ERROR']);
} else {
response['features'].forEach(feature => {
var pt = {lng: parseFloat(feature['geometry']['coordinates'][0]),
lat: parseFloat(feature['geometry']['coordinates'][1])};
console.log('cluster: ', pt, ' points: ', feature['properties']['pt_count'].toString());
});
}
} else {
console.log('show_clusters: ERROR status: ', this.status);
}
}
};
var params = 'id=' + id + '&' +
'zoom=' + zoom + '&' +
'ne_lat=' + ne_lat + '&' +
'ne_lng=' + ne_lng + '&' +
'sw_lat=' + sw_lat + '&' +
'sw_lng=' + sw_lng;
var query = 'http://localhost:3000/api/clusters?' + params;
http_request.open('GET', query);
http_request.send();
}
function bounds_changed() {
var bounds = gmap.getBounds();
var SW = bounds.getSouthWest();
var NE = bounds.getNorthEast();
var ne_lat = NE.lat();
var ne_lng = NE.lng();
var sw_lat = SW.lat();
var sw_lng = SW.lng();
show_clusters(zoom, ne_lat, ne_lng, sw_lat, sw_lng, bounds);
}
function init_map() {
gmap = new google.maps.Map(document.getElementById('map'),
{
zoom: 1,
center: { lat: -25.363, lng: 131.044 }
});
google.maps.event.addListener(gmap, 'bounds_changed', bounds_changed);
}
</script>
<script src="https://maps.googleapis.com/maps/api/js?callback=init_map"></script>
</body>
</html>
As you probably noticed in the api.js module, when getting clusters from PostgreSQL there used ST_Buffer function, which extends the bounding box on some predefined distance. This is useful when you are trying to get clusters on bounds changed events. It’s better to make one query with the extended visible area and then use cached result when the user is panning the map than flood your server with queries for every bound change.
Another thing that can speed up the clustering process is to perform hierarchical clustering. Instead of running the same clustering function on all places in your database and just changing the radius based on zoom level, we can run this function on previously clustered data. So, for example, the input points for the clustering function for the ninth zoom level would be clustered data from the tenth zoom level and so on.